
| Language | Orthography |
Orthography (romanisation) |
Phonology (IPA) |
|---|---|---|---|
| Afrikaans | masker | masker | /mɑːsk/ |
| Albanian | maskë | maskë | /maskaɾiʝa/ |
| Amharic | ጭምብል | ch'imibili | /tʃ'imibili/ |
| Arabic | قناع |
qunae | /qinaːʕ/ |
| Armenian | դիմակ | dimak | /dimɑk/ |
| Azerbaijani | maska | maska | /maska/ |
| Bangla | মুখোশ | mukhosh | - |
| Basque | maskara | maskara | /maskaɾa/ |
| Belarusian | маска | maska | /maska/ |
| Bengali | মাস্ক | māska | /mask/ |
| Bosnian | maska | maska | /maska/ |
| Bulgarian | маска | maska | /maskə/ |
| Catalan | mascareta | mascareta | /məskəɾɛtə/ |
| Cebuano | maskara | maskara | /maskaɾa/ |
| Chichewa | amabisa | amabisa | /amaɓisa/ |
| Chinese Simplified | 手术口罩 | shǒushù kǒuzhào | /ʂə̌uʂʷù kʰə̌uʈʂàu/ |
| Chinese Traditional | 手術口罩 | shǒushù kǒuzhào | /ʂə̌uʂʷù kʰə̌uʈʂàu/ |
| Corsican | maschera | maschera | /maskeɾa/ |
| Croatian | maska | maska | /màska/ |
| Czech | maska | maska | /maska/ |
| Danish | maske | maske | /masgə / |
| Dutch | masker | masker | /mɑskər/ |
| English | mask | mask | /mɑːsk/ |
| Esperanto | masko | masko | /masko/ |
| Estonian | naamio | naamio | /naːmio/ |
| Tagalog (Filipino) | maskara | maskara | /maskaɾa/ |
| Finnish (Suomi) | naamio | naamio | /nɑːmio/ |
| Finnish (Suomi) | maskara | maskara | /mɑskɑrɑ/ |
| Finnish (Suomi) | ripsiväri | ripsiväri | /ripsiˌʋæri/ |
| French | masque | masque | /mɑːsk/ |
| Frisian | masker | masker | /masker/ |
| Galician | máscara | máscara | /maskaɾa/ |
| Georgian | ნიღაბი | nighabi | /niɣɑbi/ |
| German | Maske | maske | /maskə/ |
| Greek | μάσκα | máska | /maska/ |
| Gujarati | મહોરું | mahorũ | - |
| Hausa | abin rufe fuska | abin rufe fuska | - |
| Hawaiian | pale maka | pale maka | - |
| Hebrew | מסכה |
masekháh | - |
| Hindi | मुखौटा | mukhauta | - |
| Hungarian | maszk | maszk | /mɒsk/ |
| Icelandic | gríma | gríma | /kriːma/ |
| Igbo | mkpu | mkpu | /mkk͡p~ɓ̥u/ |
| Indonesian | topeng | topeng | /topɛŋ/ |
| Indonesian | masker | masker | /maskər/ |
| Irish | masc | masc | /mɑːsk/ |
| Italian | maschera | mascherina | /maskeɾina/ |
| Japanese | マスク | masuku | /masɯkɯ/ |
| Javanese | mask | mask | - |
| Kannada | ಮಸುಕು | mukhavāḍa | - |
| Kazakh | маска | maska | /maska/ |
| Khmer | របាំង | rbang | - |
| Kinyarwanda | agapfukamunwa | agapfukamunwa | /agapfukamuŋwa/ |
| Korean | 마스크 | maseukeu | /ma̠sʰɯkxɯ/ |
| Kurdish (Kurmanji) | berrû | berrû | /beru/ |
| Kyrgyz | маска | maska | - |
| Lao | ຫນ້າກາກ | nā kāk | - |
| Latvian | maska | maska | /maska/ |
| Lithuanian | kaukė | kaukė | /kâˑʊ̯ke/ |
| Luxembourgish | mask | mask | /mask/ |
| Macedonian | маска | maska | /maska/ |
| Malay | topeng | topeng | /topɛŋ/ |
| Malay | کدوق |
kedok | /kedok/ |
| Malayalam | മാസ്ക് | māsk | - |
| Maltese | maskra | maskra | /maskra/ |
| Māori | maruhā | maruhā | /maɾuha/ |
| Marathi | लपवू | lapavū | - |
| Mongolian | маск | mask | /mask/ |
| Myanmar (Burmese) | မျက်နှာဖုံး | myakhnahpum | /mjɛʔn̥əpʰóʊɴ/ |
| Nepali | मुखवटा | mukhavaṭā | - |
| Norwegian | maskara | maskara | /maskara/ |
| Odia | ମାସ୍କ | māska | - |
| Pashto | ماسک |
mâsk-hâ | - |
| Persian (Farsi) | نقاب زدن |
mask | /mask/ |
| Polish | maska | maska | /maskɔ̃/ |
| Portuguese | máscara | máscara | /maskaɾa/ |
| Punjabi | ਮਾਸਕ | māsaka | - |
| Romanian | masca | masca | /maska/ |
| Russian | маскировать | maskirovat' | /məskʲɪrɐˈvatʲ/ |
| Samoan | ufimata | ufimata | - |
| Scots Gaelic | masg | masg | /masɡ/ |
| Serbian | маскa | maska | - |
| Sesotho | pata | pata | - |
| Shona | chifukidzo | chifukidzo | - |
| Sindhi | ماسڪ |
nutarian | - |
| Sinhala | වෙස්මුහුණ | vesmuhuṇa | - |
| Slovak | maskovať | maskovať | /maskovat/ |
| Slovenian | maska | maska | /maska/ |
| Somali | maaskaro | maaskaro | - |
| Spanish | máscara | máscara | /maskaɾa/ |
| Sundanese | topéng | topéng | /topɛŋ/ |
| Swahili | mask | mask | /mask/ |
| Swedish (Svenska) | mask | mask | /mask/ |
| Tajik | ниқоб | niqoʙ | - |
| Tamil | முகமூடி | mukamūṭi | - |
| Tatar | маска | maska | /maska/ |
| Telugu | ముసుగు | musugu | - |
| Thai | หน้ากาก | nâakàak | /naː˥˩kaːk̚˨˩/ |
| Turkish | maske | maske | /mask̟ʰe/ |
| Turkmen | maska | maska | - |
| Ukrainian | маскувати | maskuvaty | /mɑskɐ/ |
| Urdu | ماسک |
mask | - |
| Uyghur | mask | mask | - |
| Uzbek | niqob | niqob | - |
| Vietnamese | khẩu trang | khẩu trang | /kʰəw˨˩˦ ʈaːŋ˧˧/ |
| Welsh | mwgwd | mwgwd | /mʊɡʊd/ |
| Xhosa | imaski | imaski | - |
| Yiddish | מאַסקע |
maske | - |
| Yoruba | boju-abẹ | boju-abẹ | - |
| Zulu | imaski | imaski | - |
| https://drive.google.com/file/d/18SeJTiM2-JXR9SOqEg22wdkvNL3OxG3u/view?usp=sharing | |||

The ubiquity of masks has given psycholinguists a frequent-ish stimulus to use in experiments. This word is more form-similar across languages than one may think. I gathered a big-ish dataset with translation equivalents of the word mask across ~110 languages. I tweeted about this today, and wanted to dedicate some more lines to nuance.
The ubiquity of #masks😷 has given psycholinguists a frequent-ish stimulus to use in experiments. This word is more form-similar across languages than one may think. 🌐
— Gon García-Castro (@gongcastro) November 24, 2020
Here's how orthographically similar (the romanisations of) the translations of MASK are (N=110 pairs): pic.twitter.com/KMMdJke9SG
Here’s the data:
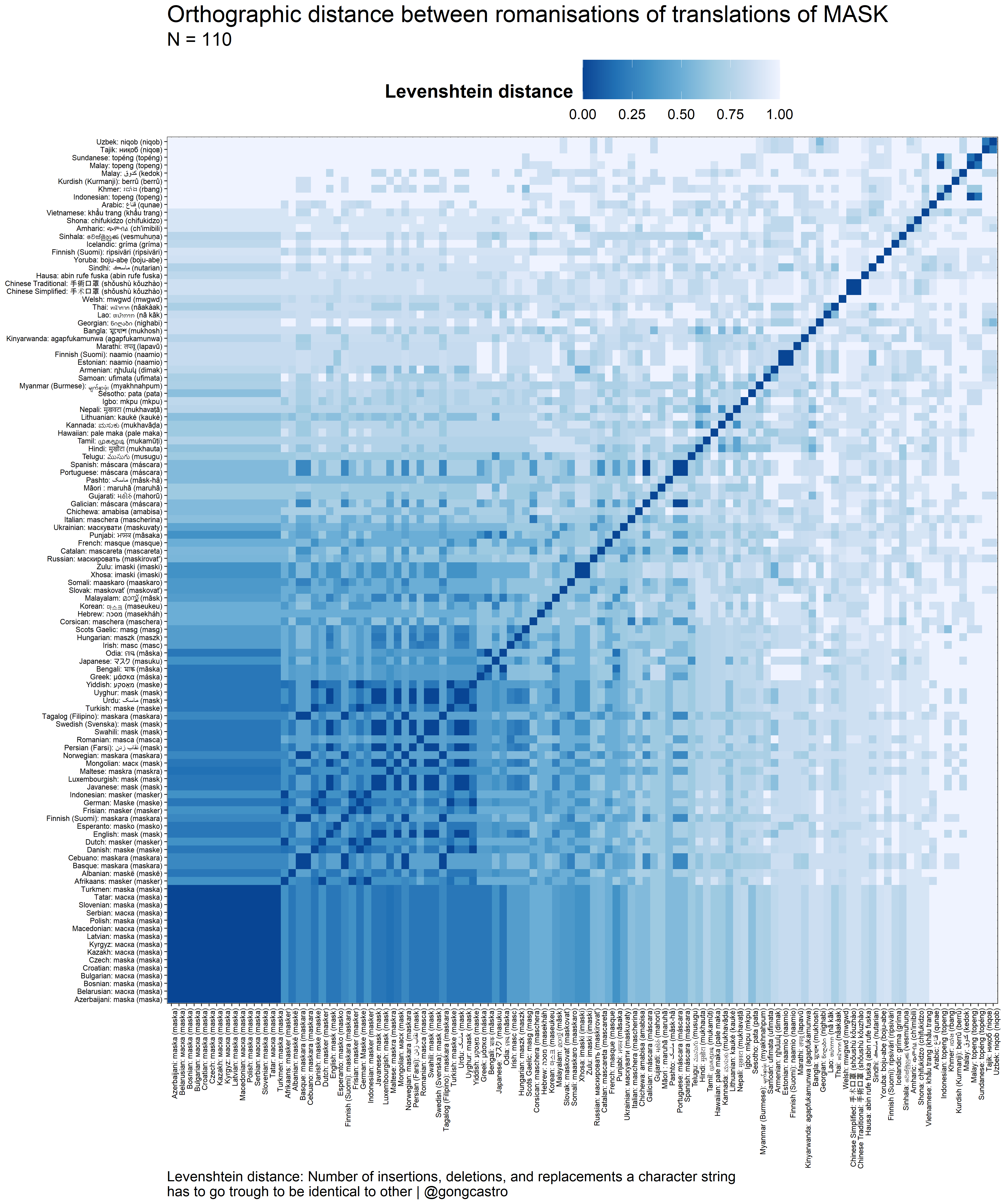
To compute the similarity of each pair of translation equivalents, I followed Floccia et al.’s (2018) procedure. For each pair of translation equivalents, I computed their Levenshtein distance as the number of insertions, deletions and replacements a string character has to go through to become identical to the other, and then divided this value by the number of characters of the longest of the two strings, so that all values range between 0 and 1. To compute the Levenshtein distance, I used the stringdist() function of the stringdist R package.
Orthographic distance
I first computed the orthographic distance between each pair of translation equivalents. Since some word forms make use of different alphabets, I first romanised all word forms. By romanised, I mean that I searched for the transcription of each word form in the Roman alphabet, and used it as input to compute the Levenshtein distance for each pair of translation equivalents. Here’s how orthographically similar (the romanisations of) the translations of mask are (N = 110 pairs):
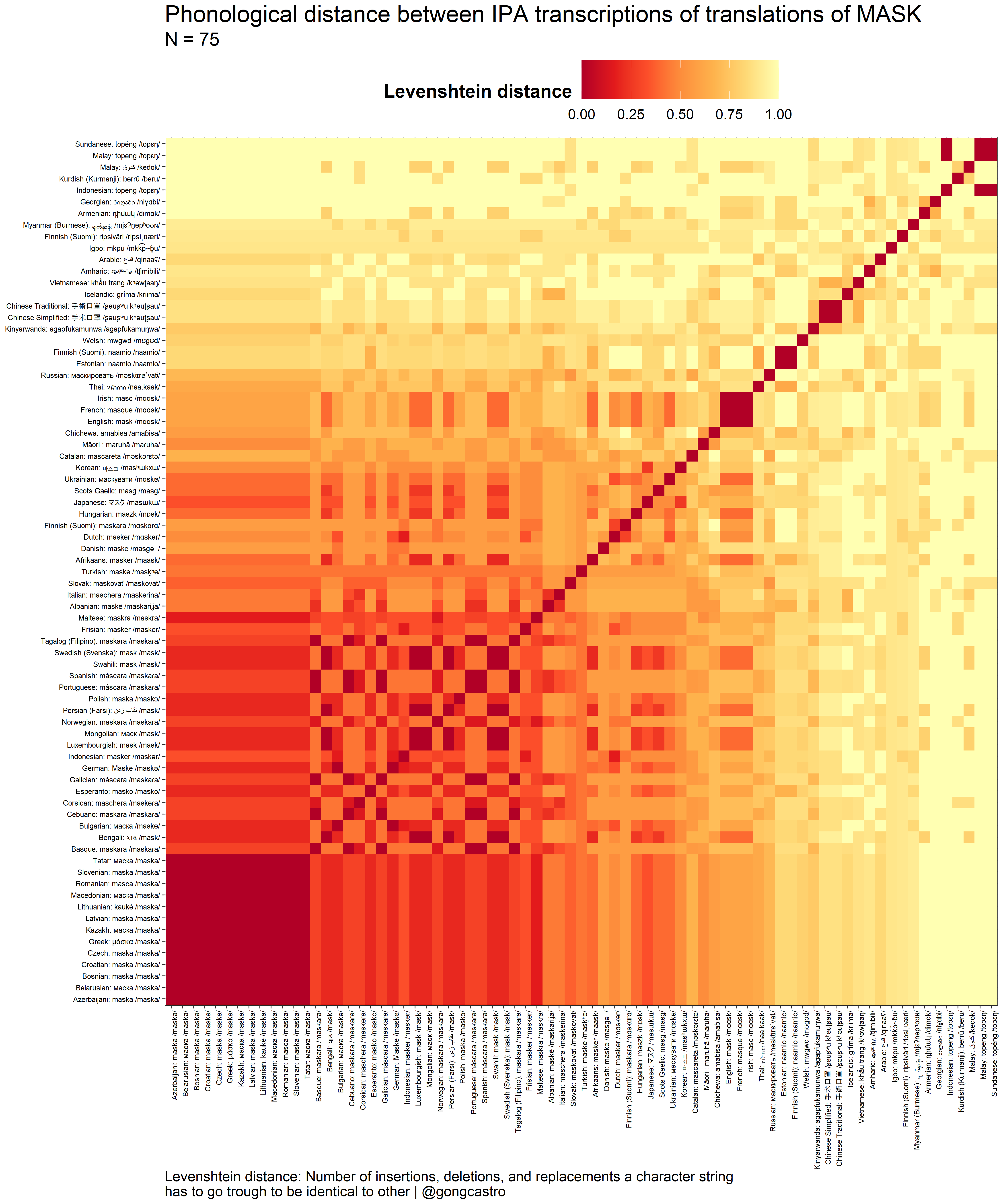
Phonological distance
The phonological similarity/distance may be more informative. This time I searched for or generated with the help of a native speaker a phonological IPA transcription of each word-form. I then used this transcription as input to compute the phonological similarity of each pair of translation equivalents. A pitfall in this process is the fact that phonemes are almost never identical across languages, so even the common phoneme /m/ could vary slightly on its pronunciation in two languages. If this difference is encoded in the IPA transcription (as different characters), the Levenshtein distance will be inflated. For this reason, I simplified some IPA transcriptions to preserve this similarity. I also removed tones. This is terribly wrong from a linguistics perspective, but it’s the only way I see to be able to play with some reliable data. Also I’m no linguist, so you have no power here.

Here’s the same analysis performed on phonological transcriptions of a subset of those languages (N = 75 pairs, those I could find a reliable IPA transcription for or could find help from a native speaker):
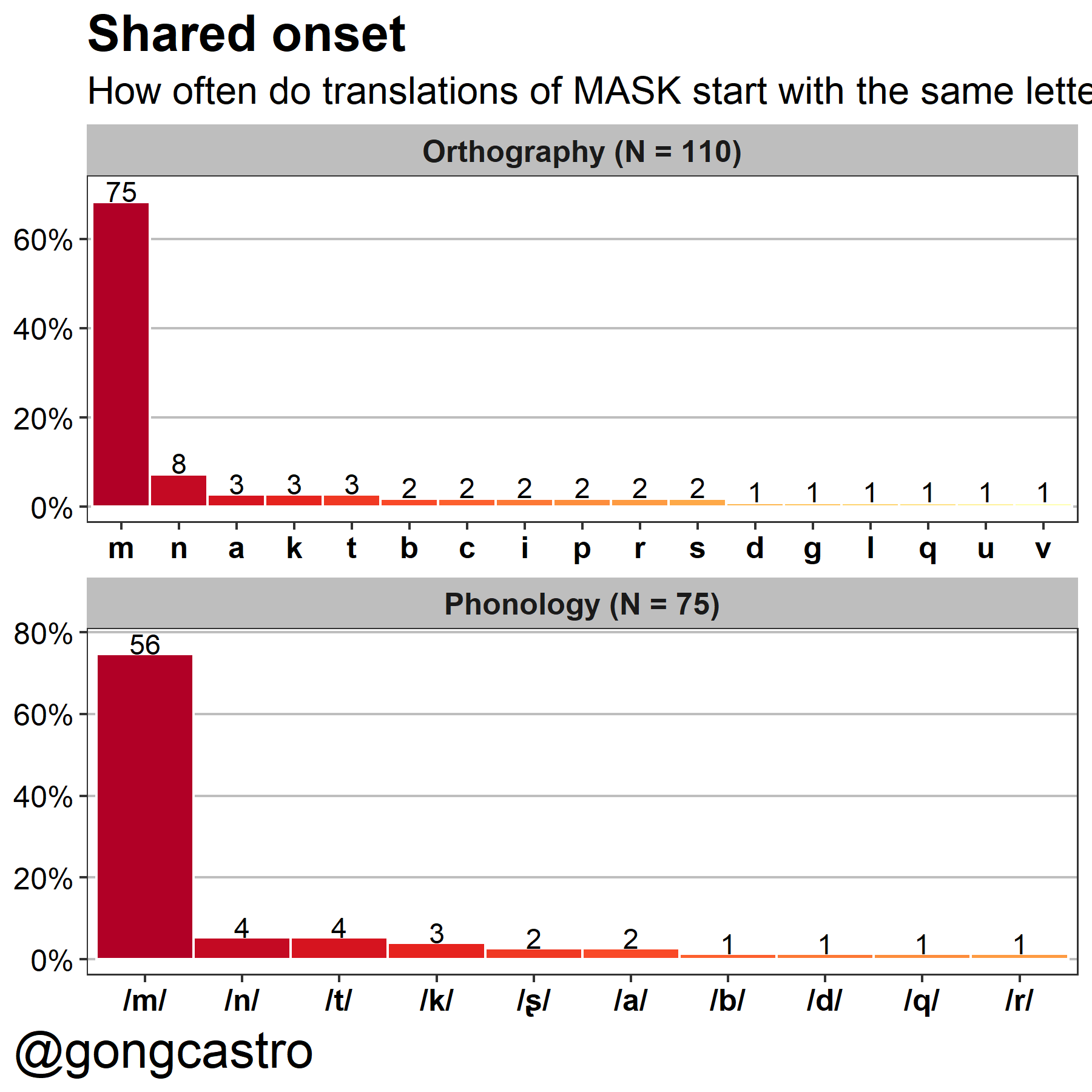
Onsets
Most of the times, the phonological overlap comes from onset graphemes/phonemes. This is how many word-forms start with each onset:
Some disclaimers:
I tried ensuring that words referred to surgical masks (instead of other types of masks) with help from native speakers. Wrong translations may still have slipped in (or be just wrong). I wish I had time to double-check all of them (I did this for fun).
This analysis is probably affected by selection bias. I suspect many dissimilar translations are missing due to not being included in the translation apps I used (e.g. Google Translate). Feel free to contribute missing entries or make corrections!
Code and data
Session info
R version 4.5.0 (2025-04-11 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 11 x64 (build 26100)
Matrix products: default
LAPACK version 3.12.1
locale:
[1] LC_COLLATE=English_United Kingdom.utf8
[2] LC_CTYPE=English_United Kingdom.utf8
[3] LC_MONETARY=English_United Kingdom.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United Kingdom.utf8
time zone: Europe/Berlin
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] htmltools_0.5.8.1 kableExtra_1.4.0 knitr_1.50 gt_1.0.0
[5] readxl_1.4.5 lubridate_1.9.4 forcats_1.0.0 stringr_1.5.1
[9] dplyr_1.1.4 purrr_1.1.0 readr_2.1.5 tidyr_1.3.1
[13] tibble_3.3.0 ggplot2_3.5.2 tidyverse_2.0.0
loaded via a namespace (and not attached):
[1] sass_0.4.10 generics_0.1.4 xml2_1.4.1 stringi_1.8.7
[5] hms_1.1.3 digest_0.6.37 magrittr_2.0.3 evaluate_1.0.4
[9] grid_4.5.0 timechange_0.3.0 RColorBrewer_1.1-3 fastmap_1.2.0
[13] cellranger_1.1.0 jsonlite_2.0.0 viridisLite_0.4.2 scales_1.4.0
[17] stringdist_0.9.15 textshaping_1.0.1 cli_3.6.5 rlang_1.1.6
[21] litedown_0.7 commonmark_2.0.0 base64enc_0.1-3 withr_3.0.2
[25] yaml_2.3.10 parallel_4.5.0 tools_4.5.0 tzdb_0.5.0
[29] vctrs_0.6.5 R6_2.6.1 lifecycle_1.0.4 htmlwidgets_1.6.4
[33] pkgconfig_2.0.3 pillar_1.11.0 gtable_0.3.6 glue_1.8.0
[37] systemfonts_1.2.3 xfun_0.52 tidyselect_1.2.1 rstudioapi_0.17.1
[41] farver_2.1.2 rmarkdown_2.29 svglite_2.2.1 compiler_4.5.0
[45] markdown_2.0 Reuse
Citation
BibTeX citation:
@online{garcia-castro2020,
author = {Garcia-Castro, Gonzalo},
title = {How Similar Is the Word “Mask” Across Languages?},
date = {2020-11-20},
url = {https://gongcastro.github.io/blog/mask-similarity-across-languages/mask-similarity-across-languages.html},
langid = {en}
}
For attribution, please cite this work as:
Garcia-Castro, G. (2020, November 20). How similar is the word
“mask” across languages? https://gongcastro.github.io/blog/mask-similarity-across-languages/mask-similarity-across-languages.html